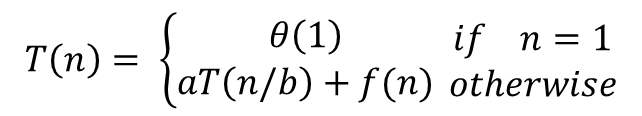그래프가 주어졌을 때 시작 노드에서부터 종료 시점까지 최단 경로를 구할때 다익스트라 알고리즘을 사용한다. 다익스트라 알고리즘은 반드시 음수 사이클이 존재하지 않아야 한다. 만약 음수 사이클이 발생할 수 있다만 벨만 포드 알고리즘을 이용해야 한다. 다익스트라는 시작점으로부터 cost에 대한 min heap을 이용하여 가장 cost가 적은 순서대로 계속해서 길을 찾아보며 만약 도착 노드를 발견하는 순간 종료된다. 코드를 보자. 이 소스코드는 백준 최단 경로를 기반으로 하고 있다. #include #include #include #include using namespace std; typedef pair pii; #define ff first #define ss second #define mp(x, y) ma..