1. Hash란?
Hash 함수는 어떤 값의 범위를 다시금 0~X까지로 매핑하는 역할을 수행한다. 이러한 Hash 함수의 역할을 통해서 범위에 비하여 값이 너무 sparse했던 애들을 압축할 수 있다. 혹은 전체 범위 중 특정 값에 몰려 있던 것을 퍼트리는 역할도 수행하 수 있다.
예를 들면 어떤 값은 알파뉴메릭 최대 30자 문자열이 10만개 있다고 하자. 그러면 이 값의 범위는 a-zA-Z0-9이므로 62^30승 ~= (2^6)^30 .....
그렇다고 이 값을 full scan하기에는 최악의 경우에는 10만 * 30자 총 300만번의 search cost가 발생한다. 그러나 해당 문자열 값을 hash 함수를 이용하여 5000개로 나누어 담을 수 있다면, 한 해쉬 값당 20개씩 문자열이 저장된다. 그렇다면 10번의 scan시에 10*10만*30 >>>> 10*20*30으로 대단히 많은 양의 cost를 줄일 수 있다. 다르게 생각해보면 20 ~= O(log 1e5) ~= O(logN)으로도 볼 수 있다.
2. Hash 테이블과 Chaining
Hash 테이블은 값 X를 hash 함수에 넣어서 나오는 해쉬 값 위치에 저장한 테이블이다. 문제는 hash 함수가 평균적으로 분산 시킬 수 있다는 뜻이지, 반드시 산술 평균 갯수로 나눠떨어지는 것이 아니다.
즉, 서로 다른 값이지만 동일한 해쉬 값을 가지는 conflict의 개수가 일정하지 않다는 점인데, 만약 공간의 여유가 있다면 상관없지만 그렇지 않은 경우라면 이전에 다루었던 Linked list를 이용하여 필요시마다 추가하거나 삭제하는 scheme을 활용해야 한다.
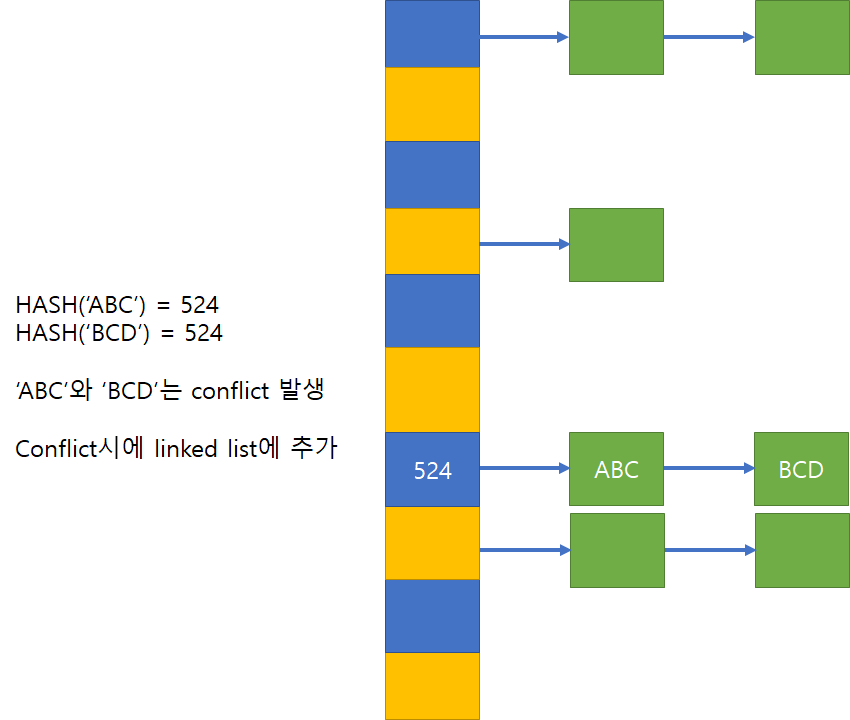
3. 기본 동작
| 함수 | 동작 |
| hashf(char *str) | 문자열 str을 받아서 0~4998 사이 해쉬값 반환 |
| _add(char *str) | 문자열 str을 받아서 hash 테이블에 삽입 |
| _search(char *str) | 문자열 str의 개수를 반환 |
| _remove(char *str) | 문자열 str을 모두 삭제 |
| _update(char *str, char *str2) | 문자열 str을 str2로 치환 |
hash함수의 경우 원하는대로 구현해도 무방하다. 나는 적당히 곱셈 후 모듈러 연산을 수행했다.
_add 함수는 해시 함수를 구하고 해당 위치에 새로운 노드를 추가하는 동작을 수행했다. 동일한 값 사이에 순서(stable)를 지키지 않아도 괜찮다면 가장 맨 앞에 push_front하고 리턴하는 것이 가장 빠르다.
_search 함수와 _remove 함수는 포인터를 이용하여 해당 리스트를 풀 스캔하며, 만약 가장 처음 나오는 1개만 처리를 한다면 내부를 적절하게 return 해버리면 된다.
그리고 delete의 경우 사용할 수 있는 메모리의 양과 할당 가능한 Node의 개수를 파악하여 만약에 재활용을 해야한다면, Node를 제거하여 새로운 배열에 제거한 node를 리스트업 해야하고 그것이 아니라면 del 플래그만 쳐놓고 리턴한다.
물론 대부분의 경우 del flag만 표시해도 충분하다.
_update의 경우에는 구현하지 않았다. search 후에 해당 위치의 값을 del하고 다시 hash 테이블에 str2를 push하면 된다.
4. 구조체
struct Node {
char s[20];
bool del;
Node *pr, *nx;
};
Node nodes[250005];
int np;
Node* table[5005];Node를 정의했고, 미리 전역으로 할당한 nodes 변수와 인덱스 저장용 np를 선언한다. 그리고 hash 테이블으로 사용하기 위한 Node 포인터 배열을 선언한다.
5. Hash 함수
int hashf(char *str) {
int r = 1;
while (*str) {
r *= *str;
r %= 4999;
str++;
}
return r;
}함수는 적당히 짜면 된다. 여기서는 각 문자열의 곱의 결과를 4999로 나눈 나머지로 이용한다.
6. add 함수
void _add(char * str) {
ztrcpy(str, nodes[np].s);
nodes[np].del = false;
nodes[np].pr = nodes[np].nx = NULL;
int h = hashf(str);
Node* cur = table[h];
if (!cur) table[h] = &nodes[np++];
else {
// push back
while (cur->nx) {
cur = cur->nx;
}
nodes[np].pr = cur;
cur->nx = &nodes[np++];
// push front
// cur->pr = &nodes[np];
// nodes[np].nx = cur;
// table[h] = &nodes[np++];
}
}새로운 노드를 초기화하고 각 리스트에 넣어주는 역할을 수행한다. 앞서 말한 것과 같이 stable하지 않아도 된다면 push_front하는 편이 훨씬 빠르다.
7. Search 함수
int _search(char *str) {
int h = hashf(str);
Node* cur = table[h];
int rst = 0;
if (!cur) return rst;
while (cur) {
if (!cur->del && ztrcmp(str, cur->s) == 0) rst++;
cur = cur->nx;
}
return rst;
}Search 함수는 리스트 전체를 순회하여 동일한 값을 가지는지 여부를 확인한 다음 개수를 반환한다.
8. Remove 함수
int _remove(char *str) {
int h = hashf(str);
Node* cur = table[h];
int rst = 0;
if (!cur) return rst;
while (cur) {
if (!cur->del && ztrcmp(str, cur->s) == 0) {
cur->del = 1;
rst++;
}
cur = cur->nx;
}
return rst;
}Remove 함수는 search와 마찬가지로 동작하지만, 동일한 값을 가지면 del=1으로 플래그 처리만하고 리턴한다.
코드
전체 코드
#include <iostream>
using namespace std;
struct Node {
char s[20];
bool del;
Node *pr, *nx;
};
Node nodes[250005];
int np;
Node* table[5005];
void ztrcpy(char *src, char *dst) {
while (*src) {
*dst = *src;
++dst; ++src;
}
}
int ztrcmp(char *str, char *dst) {
while (*str && *str == *dst) {
++str; ++dst;
}
return *str - *dst;
}
int hashf(char *str) {
int r = 1;
while (*str) {
r *= *str;
r %= 4999;
str++;
}
return r;
}
void _add(char * str) {
ztrcpy(str, nodes[np].s);
nodes[np].del = false;
nodes[np].pr = nodes[np].nx = NULL;
int h = hashf(str);
Node* cur = table[h];
if (!cur) table[h] = &nodes[np++];
else {
// push back
while (cur->nx) {
cur = cur->nx;
}
nodes[np].pr = cur;
cur->nx = &nodes[np++];
// push front
// cur->pr = &nodes[np];
// nodes[np].nx = cur;
// table[h] = &nodes[np++];
}
}
int _search(char *str) {
int h = hashf(str);
Node* cur = table[h];
int rst = 0;
if (!cur) return rst;
while (cur) {
if (!cur->del && ztrcmp(str, cur->s) == 0) rst++;
cur = cur->nx;
}
return rst;
}
int _remove(char *str) {
int h = hashf(str);
Node* cur = table[h];
int rst = 0;
if (!cur) return rst;
while (cur) {
if (!cur->del && ztrcmp(str, cur->s) == 0) {
cur->del = 1;
rst++;
}
cur = cur->nx;
}
return rst;
}
void print(int i) {
Node* cur = table[i];
while (cur) {
printf("%s(%d) -> ", cur->s, cur->del);
cur = cur->nx;
}
printf("\n");
}
char s[6];
int main() {
for (int i = 0; i < 250000; i++) {
for (int j = 0; j < 5; j++) {
s[j] = rand() % 10 + 'a';
}
_add(s);
}
printf("Search %s : %d\n", "diiii", _search("diiii"));
print(3998);
printf("Remove %s : %d\n", "diiii", _remove("diiii"));
print(3998);
system("pause");
}
'프로그래밍 > C, C++, Java, Python' 카테고리의 다른 글
| Modbus TCP 통신을 위한 프로토콜 파헤치기 & 예제 코드 (0) | 2021.02.02 |
|---|---|
| [Python] 파이썬 Socket.IO 오류 unexpected response code 400 (0) | 2021.01.16 |
| 삼성 SW 역량테스트 B형/Pro 대비 - 단방향 Linked list 만들기 (0) | 2020.12.28 |
| 삼성 SW 역량테스트 B형/Pro 대비 - C, C++ 큐 만들기 (0) | 2020.12.20 |
| [Python] IEEE754 부동 소수점 <-> 비트 변환 예제 (0) | 2019.07.14 |